2021. 9. 3. 06:48ㆍ개인 프로젝트/게임 여론 분석
[T 게임의 <언더월드> 이벤트 여론 분석 - 감성분석 편]

(이번 감성분석 편에서는 아래의 글을 많이 참고했습니다)
【실습】 Python >> Text Mining -- 감성 분류 분석 (호텔 리뷰 데이터) | Hyemin Kim (hyemin-kim.github.io)
【실습】 Python >> Text Mining -- 감성 분류 분석 (호텔 리뷰 데이터)
1. 감성 분류 예측 모델 도출 (Logistic Regression); 2. 긍/부정 키워드 추출
hyemin-kim.github.io
5. 감성분석
1) 감성분석 방향
게임 유저들의 만족과 불만을 알기 위해서는, 단순히 여론이 어떤 군집으로 형성되어 있느냐를 따지는 것만으로는 부족하다. 따라서 앞서 데이터 시각화 편에서 전체 게시글 중 상위에 속했던 단어들을 중심으로, 유저들의 긍정, 부정의 정도를 파악하고자 한다.
또한 각 데이터들을 면밀히 살펴봄으로써 유저들이 어느 부분에서 긍정하는지, 어느 부분에서 부정하는지를 파악하고자 한다.
감성분석을 위해 필요한 라이브러리는 다음과 같다.
import pandas as pd
import numpy as np
from konlpy.tag import Okt
import re
from sklearn.feature_extraction.text import CountVectorizer
from sklearn.feature_extraction.text import TfidfTransformer
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score, precision_score, recall_score, f1_score
from sklearn.metrics import roc_curve, roc_auc_score
from sklearn.metrics import confusion_matrix
import seaborn as sns
import matplotlib.pyplot as plt
%matplotlib inline
import warnings
warnings.filterwarnings('ignore')
2) 로지스틱 회귀 모델 학습
원래는 K-Fold Cross Validation(교차검증)을 이용해 여러 모델 간의 정확도를 비교해보기로 했으나, 테스트 데이터가 10만개이기 때문에 생각보다 시간이 오래 걸렸다. 따라서, 이전에 시도해본 Logistic Regression(로지스틱 회귀) 모델을 가지고 감성분석을 시도해봤다.
이때, 로지스틱 회귀 모델을 학습할 때에는 수집한 데이터와는 전혀 다른 아래의 데이터(그러나 게임에 관련한 데이터)를 사용했다.
데이터 출처: https://github.com/bab2min/corpus/tree/master/sentiment
data = pd.read_csv("https://raw.githubusercontent.com/bab2min/corpus/master/sentiment/steam.txt", sep="\t", header=None)
data.columns = ['rate', 'text']참고로 위 데이터는 Tab으로 구분되어 있으며, 열 이름이 없기 때문에 header 속성을 'False'로 지정해야 한다. 안 그러면 첫번째 행이 열 이름으로 들어가는 불상사가 발생할 수 있다. 보기 쉽게 열 이름을 바꾼 후, 데이터는 다음과 같이 변했다.

이때, rate열에서 0이 부정, 1이 긍정을 의미한다.
감성분석을 진행하기 위해, text열에서 불필요한 문자(문장부호, 특수문자 등)를 제거하기 위해 함수를 지정하고, 지정된 함수를 이용해 문자열을 바꿨다.
def text_cleaning(text):
hangul = re.compile('[^ ㄱ-ㅣ가-힣]+') #공백과 한글 제외
result = hangul.sub('', str(text)) #공백과 한글 제외 나머지 삭제
return result
data['text_clean'] = data['text'].apply(lambda x: text_cleaning(x)) #data의 text열의 각 행에 대해 위 함수 적용결과는 다음과 같다.

보면 한글과 공백을 제외한 문장부호 등은 제거된 것을 확인할 수 있다.
이제 다음으로는 토큰화를 진행했다. 즉, 문장 중에서 불필요한 형태소(혹은 품사)를 제거하고 필요한 품사만 남기는 작업을 진행했다.
sent_list = []
okt = Okt()
for line in data['text_clean']:
result = okt.pos(str(line), norm=True, stem=True) #okt 분석기로 각 단어 별 품사 지정
token = []
for word in result:
if (len(word[0]) > 1) and ((word[1] == "Noun") or (word[1] == "Adjective") or (word[1] == "Verb")):
token.append(word[0]) #2글자 이상이고, 명사나 형용사나 동사인 단어만 token 열에 append
sent_list.append(" ".join(token)) token 열에 있던 단어들을 공백으로 한 문자열로 연결해 send_list에 저장대체로 긍정과 부정은 명사, 형용사에서 결정되며, 또한 동사도 필요하다고 생각했기에 명사와 형용사, 그리고 동사만을 이용했다. 이렇게 해서 만들어진 sent_list 는 다음처럼 생겼다.

이제 이 데이터를 이용해 감성분석 학습을 진행할 예정이다.
하지만 그 전에 위 데이터를 벡터로 바꾸어야 한다. 위 프로젝트에서는 Count Vectorizer이랑 TF-IDF Vectorizer을 시행했다.
count_vectorizer = CountVectorizer()
X = count_vectorizer.fit_transform(sent_list)
tfidf_vectorizer = TfidfTransformer()
X = tfidf_vectorizer.fit_transform(X)Count Vectorizer은 입력된 모든 단어들에 대해 빈도수를 계산하고, 각 문장 별로 단어들이 몇 번 나왔는지를 이용해 문자를 벡터화하는 용도다.
또한 TF-DF Vectorizer은 단어의 빈도수와 단어의 흔함 정도에 따라서 문자를 벡터화하는 용도다. 특정 단어가 문서 내에서 자주 등장하면 가중치는 높아지나, 단어 자체가 조사나 접속사처럼 문서 전체에서 많이 사용되면, 가중치가 낮아지는 방식이다. 어떤 단어의 가중치가 높다는 것은, 그 단어는 해당 문서(문장)에서 핵심적인 역할을 한다는 의미로도 해석이 가능하다.
그러므로 위 2가지 방식을 통해, 이미 긍정과 부정으로 분류된 문장들 각각에서 어떤 단어가 가중치가 높은지, 즉 핵심 단어인지를 알 수 있다.
전체 입력 데이터를 벡터로 바꾸었기 때문에, 이제 라벨 데이터도 준비하고 훈련 데이터/평가 데이터로 나누어야 한다.
Y = data['rate']
x_train, x_test, y_train, y_test = train_test_split(X, Y, test_size=0.2, stratify=Y)Y는 data 데이터의 rate열, 곧 긍정과 부정을 나타내는 값이다. 그리고 sklearn의 train_test_split 메소드를 사용해 훈련 데이터와 평가 데이터로 나누었다. 이때, 훈련 데이터와 평가 데이터 간의 라벨 비율을 비슷하게 조정하고자 'stratify=Y' 파라미터를 추가했다.
평가 데이터 비율은 0.2로, 곧 훈련 데이터와 평가 데이터는 8:2 비율이 된다.
입력 데이터와 라벨이 모두 준비되었기에, 이제부터 로지스틱 회귀 모델에 해당 데이터들을 적용하여 훈련을 시킬 수 있다.
from sklearn.linear_model import LogisticRegression
log = LogisticRegression(penalty = "l2")
log.fit(x_train, y_train) #훈련
y_pred = log.predict(x_test) #평가 데이터 예측
y_pred_prob = log.predict_proba(x_test)[:, 1]참고로 로지스틱 회귀 모델에는 과대적합을 방지하기 위한 방법으로 '규제'가 있는데, L1 규제와 L2 규제가 존재한다. 이 프로젝트에서는 L2 규제를 사용했다.
위 모델의 예측 결과를 확인해보니 다음과 같았다.
accuracy: 0.762
precision: 0.756
recall: 0.774
f1 score: 0.765
사실 정확도도 76%밖에 나오지 않기 때문에 그렇게 정확하고 좋은 모델은 아니다.
다른 척도로, ROC Curve를 그래프로 그렸다.

ROC Curve 그래프에서는 그래프 아래의 면적이 1에 가까울수록(왼쪽 상단으로 치우칠수록) 해당 모델의 성능이 좋다고 판단한다. 참고로 위 그래프에서는 AUC, 즉 ROC Curve 아래 면적의 값이 0.843으로 꽤 높게 나왔다.
3) 모델 저장과 로드
import pickle
import joblib
import dill
#모델 저장
joblib.dump(log, 'log_model.pkl')
with open('log_tfidfvectorizer_model.pkl', 'wb') as f:
dill.dump(tfidf_vectorizer, f)
with open('log_countvectorizer_model.pkl', 'wb') as f:
dill.dump(count_vectorizer, f)
#모델 로드
log_model = joblib.load("log_model.pkl")
with open("log_countvectorizer_model.pkl", 'rb') as f:
count_model = dill.load(f)
with open("log_tfidfvectorizer_model.pkl", 'rb') as s:
tfidf_model = dill.load(s)중간에 굳이 모델을 저장할 필요는 없으나, 이 작업을 하루에 연속적으로 수행할 것이 아니라면 저장을 해주는 것이 좋다. 모델을 저장하고 로드하는 부분은 감성분석과는 별개의 부분이기에, 여기에서는 부가적인 설명은 하지 않을 예정이다.
여기서는 로지스틱 회귀 모델은 log_model 변수로, Count Vectorizer 모델은 count_model, TF-IDF Vectorizer 모델은 tfidf_model 변수에 할당했다.
4) 감성분석
이제 본격적으로 수집한 T 게임 데이터에 대해 감성분석을 진행할 예정이다. SNS에서 모은 모든 데이터를 사용할 예정이므로, 앞서 전처리를 했던 모든 데이터를 로드하고 하나로 합쳤다.
runner_data = pd.read_csv("runner_final.csv")
cafe_data = pd.read_csv("cafe_final.csv")
tweet_data = pd.read_csv("tweet_final.csv")
#한 Series로 합치기
total_data = pd.concat([runner_data['body'], cafe_data['body'], tweet_data['tweet']])
#데이터프레임으로 변환
total_data = pd.DataFrame(total_data, columns=['text'])위 과정을 거치면 다음과 같은 데이터프레임이 나온다.

여기에서, 앞서 시각화를 통해 자주 등장했던 단어에 대한 긍정과 부정의 정도를 알아볼 예정이다. 먼저는 앞서 전체 게시글 중 상의 3개의 단어였던 '코인', '던전', '열쇠'와, 추가적으로 분석해볼 만한 가치가 있다고 느낀 '레이드', '지렁이', '문제', '확률' 키워드에 대해 분석을 진행했다.
(1) 코인
#text 열에 '코인'이라는 단어가 들어간 행들만 추출
coin = total_data[total_data['text'].str.contains("코인")]
#각 행에 대해 text_cleaning 함수를 적용해, 한글과 공백만 남김
coin['text_clean'] = coin['text'].apply(lambda x: text_cleaning(x))
#각 행에 대해 2글자 이상의 명사나 형용사, 동사만 남기고 이를 text_token 열에 할당
coin_list = []
for line in coin['text_clean']:
result = okt.pos(str(line), norm=True, stem=True)
token = []
for word in result:
if (len(word[0]) > 1) and ((word[1] == "Noun") or (word[1] == "Adjective") or (word[1] == "Verb")):
token.append(word[0])
coin_list.append(" ".join(token))
coin['text_token'] = coin_list'코인' 키워드가 들어간 글들에 대해 감성분석을 진행하려면, 앞서 로지스틱 회귀 모델을 학습했을 때와 똑같은 과정을 거쳐야 한다. 따라서 똑같은 과정을 통해 이와 같이 문자열을 바꿔주었다. 여기까지의 데이터프레임을 확인해보면 다음과 같다.

여기서 실제 감성분석에 사용할 열은 text_token 열이다. 위 열에 대해 학습할 때처럼 Count Vectorizer, TF-IDF Vectorizer, Logistic Regression 모델을 순차적으로 적용해준다.
x_test = count_model.transform(x_test)
x_test = tfidf_model.transform(x_test)
result = log_model.predict(x_test) #실제 열에 대한 감성분석 결과
coin['result'] = result #감성분석 결과를 result 열에 넣음아래와 같이 불러온 모델을 통해 transform을 거친 후, 실제 열에 대해 긍정과 부정을 예측했다.
이를 그래프로 그리면 다음과 같이 나온다.

여기서 '부정'적인 글은 11개로, '긍정'적인 글은 23개로 예측이 되었다.
각 데이터에 대해 세부적으로 살펴보기로 한다.

먼저 부정적인 글에서는, 주로 '지렁이' 아이템이나 '상자' 아이템을 사용했는데 부정적인 결과가 나와서 작성한 글이 많다. 특히 33번의 글은 이벤트 전반적으로 코인 수급이 제대로 되지 않는다는 의견이 적혀있다.

긍정적인 글 목록은 다음과 같다. 감성분석 모델이 완벽하지는 않아, 부정적인 글도 긍정적이라고 분류된 것을 볼 수 있다. 긍정적이라고 제대로 분류된 글들을 보면, 주로 '지렁이' 아이템을 통해 코인도 수급되고 결과가 좋게 나왔다는 글이 많았다.
다른 키워드에 대해서도 이와 동일한 방식을 적용했다.
(2) 던전

'던전' 키워드에 대해서는, 부정적인 글은 8개, 긍정적인 글은 17개로 분류되었다.
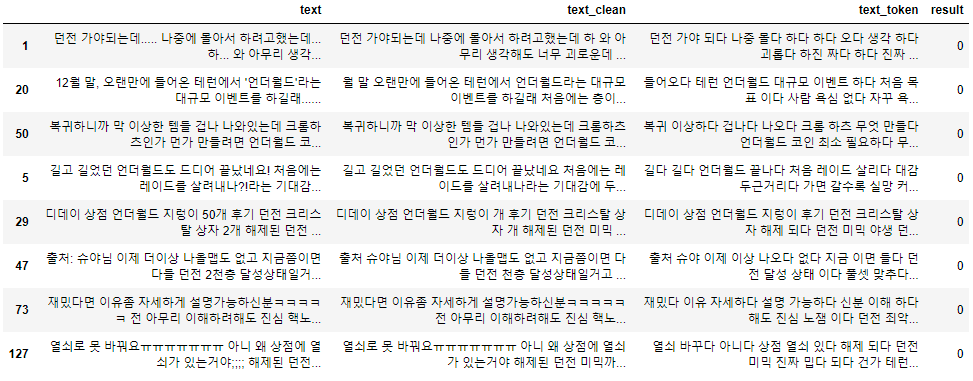
부정적인 글에 대해서는 '괴롭다', '레이드 실망했다', '노잼이다'와 같은 얘기들이 존재한다.

반대로 긍정적인 글에는 '던전 결과 만족', '애정 많이 쏟았다' 등 얘기도 많았고, 또한 '지렁이' 아이템 관련 글과 '상자' 아이템 관련 글도 중복해서 보였다.
(3) 열쇠

'열쇠' 키워드에 대해서는, 부정적인 글이 12개, 긍정적인 글이 17개로 나왔다.

부정적인 글에 대해서는 '(보물방 전용) 열쇠 없는데 보물방 나와 화난다', '상자(혹은 지렁이) 아이템 사용했는데 열쇠 등만 나왔다'와 같이 열쇠 아이템이 나오는 확률 아이템(지렁이, 상자) 등에 대한 부정적인 글이 있다.

긍정적인 글 목록에는 생각보다 열쇠에 관해 긍정적인 글이 존재하지 않았다. 대부분 부정적인 글이지만 잘못 분류된 글이며, 특히 34번 같은 경우는 '코인만 필요했으나 열쇠 3개만 떴다'는 상황을 통해, 비록 '좋네요'라는 단어를 적었지만 부정적인 상황임을 예측해볼 수 있다.
(4) 레이드
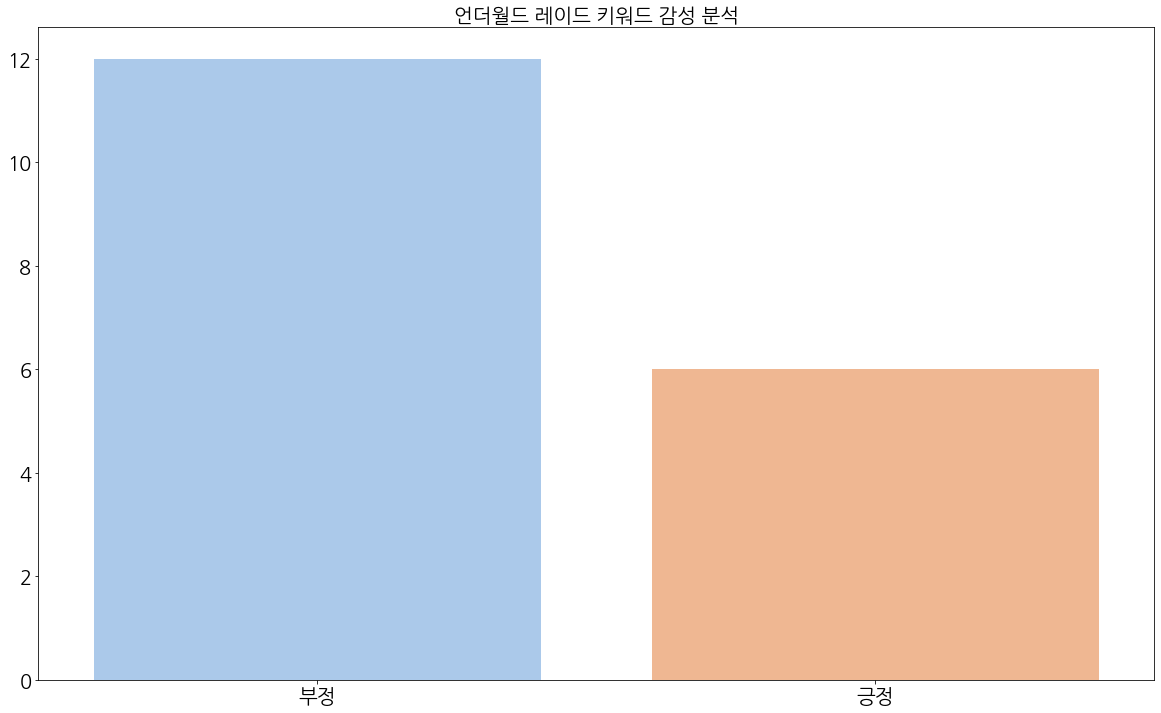
반면, '레이드' 키워드에 대해서는, 부정적인 글이 12개, 긍정적인 글이 6개로 분류되었다.

부정적인 글에서는 특히 '언더월드 리그' 이벤트 얘기 역시 나왔으며, 리그에 대해서는 '잘못되었다', '싫다'는 얘기가 있다. 또한 '또 레이드냐', '노잼이다'는 얘기가 있다.

반면 긍정적인 글에서는 반대로, '레이드 기대된다', '레이드 나오면 좋겠다'와 같이 레이드에 대한 긍정적인 글이 보였다.
(5) 지렁이
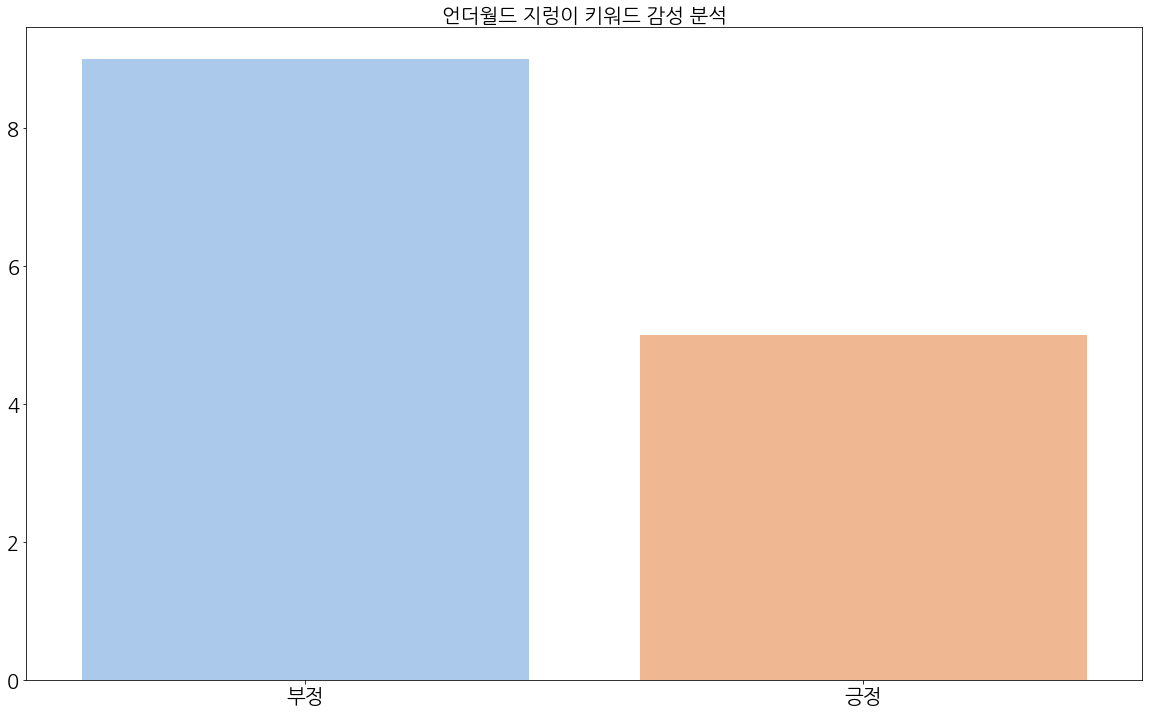
'지렁이' 키워드에 대해서도 부정적인 글은 9개, 긍정적인 글은 5개로 분류되었다.

부정적인 글을 본 결과, '지렁이' 아이템을 썼는데 '확률이 별로다', '결과가 별로다'와 같은 지렁이 관련한 부정적인 글이 많이 보였다.

긍정적인 글을 본 결과, 부정적인 결과에 대한 글이지만 잘못 분류된 글들이 많이 보인다.
(6) 문제

'문제' 키워드에 대해서는 부정적인 글은 3개, 긍정적인 글은 2개로 분류되었다.

부정적인 글을 살펴본 결과, '문제' 키워드에 맞게 이벤트에 대한 문제가 적혀있는 글들이 보였다.

긍정적인 글을 본 결과, 두 글 역시 모두 부정적인 글이나 '긍정'으로 잘못 분류된 경우로서, 레이드와 전반적인 이벤트의 문제점에 대한 글이 존재한다.
(7) 확률

'확률' 키워드에 대해서는 부정적인 글이 4개, 긍정적인 글이 2개로 분류되었다.

부정적인 글을 살펴본 결과, 상자나 지렁이 등 확률 아이템에 대해 확률이 낮다는 부정적인 글이 포함되어 있었다.

반면 긍정적인 글을 살펴본 결과, 원하는 아이템을 얻은 글과 스토리에 관한 글이 전부였다.
(8) 보상

마지막으로 '보상' 키워드에 대해서는 부정적인 글만 9개 존재했다.

해당 부정적인 글들을 본 결과, 역시 '노잼이다' 라는 글도 보이며, '보상 오류'에 대한 글들도 보인다. 혹은 '보상이 애매하다'는 글도 보인다. 특히나 18번은 보상을 받기 위해서 게임을 제대로 뛰지 않는 유저를 비판하는 글임을 예측할 수 있다.
5) 감성분석 결과
전처리한 글들에 대해 감성분석한 결과, 우선 모델이 완벽하지 않아 일부 부정적인 글 역시 '긍정'으로 분류된 점이 아쉽다. 이 부분에 대해서는 계속 실력을 쌓으면서 정확도를 높이려고 노력해야겠다.
이와는 별개로, 여러 키워드로 살펴봄에도 유저들이 어떤 부분에서 불만을 가지고 있는지 파악할 수 있었다. 특히 '레이드', '리그', '지렁이', '확률', '상자' 등에서 부정적인 여론이 형성되는 것을 확인할 수 있었다.
-여담-
프로젝트를 기획하던 6월 초에는 감성분석을 진행할 생각이 전혀 없었지만, 이번 방학 때 감성분석을 시도해봤기 때문에 이번 프로젝트에서도 감성분석을 시도해봤다. 그러나 생각보다 좋은 결과를 나오게 하는 것은 역시 힘든 것 같다. 자연어 처리에 대해 더 공부하고 시도해봐야겠다는 생각이 들었다.
'개인 프로젝트 > 게임 여론 분석' 카테고리의 다른 글
| [파이썬] T 게임의 <언더월드> 이벤트 여론 분석 - 결론 편 (0) | 2021.09.14 |
|---|---|
| [파이썬] T 게임의 <언더월드> 이벤트 여론 분석 - 군집화 편 (0) | 2021.09.03 |
| [파이썬] T 게임의 <언더월드> 이벤트 여론 분석 - 데이터 시각화 편 (2) | 2021.08.29 |
| [파이썬] T 게임의 <언더월드> 이벤트 여론 분석 - 데이터 전처리 편 (0) | 2021.08.28 |
| [파이썬] T 게임의 <언더월드> 이벤트 여론 분석 - 데이터 수집 편 (풀버전) (0) | 2021.07.23 |