2023. 5. 17. 10:18ㆍ연구 프로젝트/논문 정리
1. Introduction
*챗봇이 더 인간처럼 작동할 수 있도록 하는 중요 요소: empathy, 공감
-특히 "잠재적인" 감정을 이해하는 것이 중요함
-그럼 공감이란 무엇일까? "상대방의 정서적인 상태에 따라 감정적으로 반응할 수 있는 능력"
=> 공감적인 챗봇을 구현할 시 speaker와 listener 역할 & 대화 이후 이 둘 간의 감정 상태 변화를 고려해야 함
*본 논문의 기여
① 사용자의 공감을 증폭하고, 두 대상이 느낄 미래의 감정 상태 사이의 가능한 변화를 고려하기 위해, 인간을 시뮬레이션하는 RL 에이전트 설정(Conceptual Humans Model)
② 실험 결과는 CheerBots이 EmpatheticDialogues 데이터셋을 이용했을 때 최첨단 성능을 달성함을 증명함
3. Empathetic Chatbot
1) Framework Overview

*프레임워크에는 4가지의 주요 구성 요소가 존재함
① Emotion Controller: 입력 문장에 알맞는 감정을 감지하고, 다음 감정을 예측함 (챗봇이 더 공감적인 반응을 하도록)
② Response Generator: 답변을 생성하기 위해 입력 문장 및 예측된 다음 감정을 고려함
③ Comceptual Human Model (CHM): 대화 속에서 인간을 시뮬레이션하며, 발화자가 반응할 가능성이 있으며 위 입력에 대응되는 답변을 반환함
④ Empathy Amplifier: 입력 문장과 해당 입력에 대응된 답변 사이의 감정 차이를 측정
-> deep RL(심층 강화학습) 기반의 Next Emotion Predictor을 미세 조정하는 공감가(empathy valence)를 최대화함으로써 챗봇이 공감을 하도록 만듦
2) Emotion Controller
*감정과 관련된 프로세스를 담당하며, 2개의 장치로 구성됨
(1) Emotion Detector
*Valence-Arousal 좌표를 기반으로 한 Valence-Arousal (VA) 투영을 사용함
*각 감정은 2차원의 벡터로 표현됨
*언어 이해를 향상하기 위해 BERT로 훈련됨
*현재 입력 문장 Sinput의 감정과 그에 대응되는 VA를 감지하는 데 사용됨
*2가지 손실 함수를 사용: 서로 다른 가중치 Lc를 갖는 cross-entropy loss Ld와 L2 norm loss로 구성됨
-Ld: 분류를 위한 cross-entropy 손실을 나타냄
-Lc: 예측을 위한 VA 좌표를 나타냄
*입력 시퀀스 xi와 Ground Truth gi가 주어졌을 때, 감정 분류 테스크를 담당하는 모델을 미세 조정함
-> Ld에 의해 입력 문장으로부터 감정을 분류
-Ld loss는 모든 학습 문장의 negative log-likelihood 값을 합하고, 각 class의 분류 오류가 날 시 동등하게 패널티를 부여함
-L2 norm 손실을 계산하기 위해, 분류 레이어 이후에 Valence-Arousal 투영 레이어를 추가함

-V, A: 시퀀스 xi의 감지된 감정 혹은 Ground Truth emotion gi에 따른 projected valence, arousal values
-분류 결과 레이어에서 최대 확률을 갖는 라벨이 최종 감정 라벨이 됨
(2) Next Emotion Predictor
*목표: Response Generator로 반응을 생성할 수 있도록 입력 문장에 대응되는 감정을 예측
*Emotion Detector와 동일한 구조의 BERT로 학습
*입력 문장 Sinput과 감지된 감정 Enow가 주어질 때, BERT 인코더에 의해 임베딩된 의미 벡터와 원-핫 감정 class를 1개의 벡터로 연결
-> 이후 다음 감정의 확률을 예측하기 위해 linear classifier에 위 벡터를 입력
*감정 예측 손실을 측정하기 위해 Emotion Detector와 동일한 cross-entropy 손실 적용
-> Response Generator: 공감을 불러 일으키는 적절한 감정과 함께 반응 가능
3) Response Generator
*목표: 주어진 예측된 감정에 따라 응답을 생성
*retrieval chatbot & generative chatbot 둘 다 사용
(1) Retrieval-based Chatbot
*맥락 X가 주어질 때, 응답 후보군 Y 중 최적의 반응(답변) 선택
-X, Y 둘 다 인코딩하기 위해 BERT 인코더 적용
-맥락 X: x1, x2, ...으로 토큰화, 토큰들은 hx으로 인코딩됨
-후보군 Y: y1, y2, ...으로 토큰화, 토큰들은 hy으로 인코딩됨
*후보 yi 중 적절한 답변 선택하기 위해 softmax 함수 사용 및 negative log-likelihood를 최소화하는 목적함수를 아래와 같이 정의

*학습 시 negative sample을 설정하기 위해, 같은 batch 내 다른 후보들을 negative sample로 사용
*특정 감정에 대한 답변을 생성하기 위해, 주어진 감정을 기반으로 한 답변 후보를 검색하는 데 사용될 Emotion Filter 적용
*응답 후보군 내 모든 후보는 몇몇 그룹으로 분할됨
*Emotion Filter: Next Emotion Predictor에 의해 예측된 감정에 대응하는 특정 감정 그룹으로부터 후보군을 검색
(2) Generative-based Chatbot
*OpenAI GPT 구조 적용
*추가적인 감정 SP를 흔한 generative chatbot 포맷에 적용함으로써 모델의 consistency, engagement 향상
-대화 history segment SH와 Ground Truth reply SR을 포함해, 각 입력 시작 부분에 customized persona(ex. "I like to help people") 연결
-customized persona을 이용해, 답변하는 동안 챗봇이 인간처럼 타인을 배려하도록 성능 향상
※customized persona를 어떻게 구하지?
*학습 손실 합수는 language model(LM), next-sentence prediction(NSP), emotional sentence generation(ESG) loss로 구성됨

-LLM: 언어 모델 학습 시 cross-entropy 손실로 계산됨
-LNSP: 데이터셋에서 오답 선택지로부터 오답 문장 임의대로 추출한 후, 입력 시퀀스가 적절한 답변 or 오답으로 끝나는지 구분하기 위해 모델 인코더 학습. binary cross-entropy를 통해 local context 뿐만 아니라 global segment도 탐색하게 함
*특정 감정에 대한 답변 생성 위해, 학습 가능한 단어 임베딩에 단어 감정 라벨 추가
-cross-entropy를 사용해 인코딩된 벡터가 가정된 라벨과 일치되도록 보장하기 위해, 입력 문장 내 감정 라벨을 가정하고, 감정 분류 손실 LESG를 추가
∴입력 포맷은 3개의 segment, 1개의 감정 라벨로 구성됨
∴3개의 다른 손실 함수를 통해 타겟 시퀀스 y_hat 예측 가능
4) Conceptual Human Model (CHM)
*인간의 행동 시뮬레이션하기 위해 제작
*conceptual agent로써 발화자의 가능한 미래 답변 Sreact을 얻을 수 있음
-conceptual model = agent: 행동과 상호작용을 포함하며, 구현의 의미를 더 높은 수준의 추상화로 설명함
-발화자의 행동을 시뮬레이션하기 위해 generative-based chatbot 사용
*Response Generator와 같은 학습 접근법 사용, but CHM과 RG간 차이점
-학습 입력 포맷: RG 내 chatbot은 청취자의 문장을 학습 답변으로 사용, but CHM은 발화자의 문장을 학습 답변으로 사용
-persona: 입력 포맷의 persona 부분에서, generative-based chatbot은 self-defined persona 적용, but CHM은 ED 데이터셋에서 제공하는 발화자의 simulation prompt를 대화 상황으로써 사용
5) Empathy Amplifier
*잠재된 감정을 학습하기 위해, 인간의 상호작용 사이 이타적인(altruistic) 행동 고려
-이타적인 행동: 대화 주체 간의 상호작용을 나타냄
-잠재된(underlying) 감정: 대화 주체의 감정 상태 사이의 변화를 암시
*CheerBots은 발화자의 현재 감정 상태 V(Sinput)와, 그에 뒤따르는 감정 상태 V(Sreact) 간의 차이 구할 수 있음
=> 이 차이를 empathy valence R로 표현

*대화 주체간의 다른 감정 상태 변화 내 공감은 어떻게 변하는지를 구하기 위해 multi-turn 대화 고려
-multi-turn 대화를 위해, 발화자로부터 몇몇 감정 상태 구할 수 있음: VSinput, VS1input, VS2input, ..., VSninput(n: 대화 턴 수)
=> 각 턴마다의 empathy valence를 집계함으로써, multi-turn 대화 내 최종 empathy valence를 구할 수 있음
*Next Emotion Predictor를 미세 조정하기 위해 empathy valence R을 강화학습의 최종 보상으로 활용
-Policy gradient (PG), deep Q-learning (DQN)을 이용해 deep RL 알고리즘 수행
4. 실험 설정
1) Dataset
(1) Empathetic Dialogues Dataset
*32개의 서로 다른 감정 라벨 포함
-유사한 감정 라벨은 서로 통합 (ex. "prepared" -> "confident", "sentimental" -> "nostalgic", "terrified" -> "afraid")
2) 모델 학습
(1) Valence-Arousal Coordinate Projection
① Emotion Detector를 지도학습
② 학습된 Emotion Detector로부터 pseudo 라벨을 예측함으로써 남는 감정 획득
=> 감정을 VA 좌표에 맵핑하는 또다른 Emotion Detector 학습 가능
(2) Training detail
*사전학습된 Emotion Detector, Next Emotion Predictor, Response Generator, CHM 로드
-Next Emotion Predictor만 학습 가능, 반면 다른 모델의 가중치는 고정됨
*Response Generator: retrieval model or generative model 다 가능
-generative model: PersonaChat & ED 데이터셋으로 미세 조정된 유일한 모델
-> ED 데이터셋으로 미세 조정
3) 모델 평가 설정
*2가지 방식으로 모델의 성능 평가: automatic metrics, human ratings
(1) Automatic metrics
*Response Generator에 의해 생성된 응답을 가지고 문장 수준의 BLEU 점수 계산
-> ED 데이터셋 내의 실제 답변과 비교
*Generative-based model에 대해서는 perplexity 확인 & retrieval-based chatbot 내 P@1,100 계산
-P@1,100: 100개의 후보 응답 중 옳은 응답을 검색하는 정확도
-P@1,100 계산 시 retrieval-model에서 사용하는 다른 모든 metris과 다르게, 옳은 응답을 후보군에 포함
(2) Human Ratings
*참가자들은 다양한 대화를 받음
-각 대화: 발화자의 시작 상태(Sinput), 대응되는 응답(Sres), 이전 응답을 기반으로 한 답변(Sreact) 포함
*참가자들은 2가지 테스크 수행
① Independent Comparison: 각 응답에 대해 관련성, 유창성을 기반으로 1~5 점수 측정
② Pairwise Comparison: 동일한 Sinput에 대해, 두 모델의 서로 다른 응답을 포함하는 몇몇 짝 설정. 참가자들은 더 공감하는 응답을 선택 (=> 전체 대화에 따라 발화자의 공감 수준의 향상 점수화 가능)

-Ground Truth: ED 데이터셋으로부터 추출된 인간 답변 예시
-Left, Tie, Right: 왼쪽 모델 선택 비율, 아무것도 선택하지 않은 비율, 오른쪽 모델 선택 비율

∴위 논문에서 제시한 모델은 ED 데이터셋으로부터 추출한 답변 예시보다 더 공감적인 응답을 제시함
5. 결과 및 논의
1) Automatic Metric result

*Retrieval
① Baseline: 논문[16]에서 사전학습된 모델
② Finetuned: BERT 모델을 이용해 [16]을 기반으로 재구축된 본 논문의 모델
③ Finetuned-EF: 오직 예측된 감정으로부터 응답 후보들 검색하기 위한 Enotion Filter을 추가해 미세 조정된 모델
④, ⑤ PG-Finetuned, DQN-Finetuned: deep RL로 미세 조정된 모델, 발화자로부터 emotion valence의 변화 또한 고려
*Generative
① Baseline: 논문[16]에서 제안된 미세 조정된 모델
② CAiRE: 논문[12]에서 제안된 모델
③ Finetuned: ED dataset으로 미세 조정된 모델
④ EmoPrepend: emotion prepending과 emotion classification loss와 함께 학습된 모델
⑤, ⑥ PG-Prepend, DQN-Prepend: deep RL로 미세 조정된 모델
*RL을 기반으로 미세 조정된 generative 모델은 P@1,100의 점수는 상대적으로 낮으나 평균 BLEU 점수는 기준보다 높음: deep RL이 보상에 더 중점을 두기 때문
=> 미세 조정된 Next Emotion Predictor가 Ground Truth과는 다른 감정을 예측하는 경우 발생
-그럼에도 본 논문에서 제안된 평균 BLEU 점수는 다른 모델 능가
-RL을 기반으로 한 모델의 perplexity 점수는 상대적으로 높으나, 평균 BLEU 점수 역시 다른 미세 조정 모델보다 높음: RL 기반 접근법이 공감을 더 강조할 수 있기 때문 & Ground Truh 문장이 공감하는 방식으로 수집되므로 RL 기반 모델은 Ground Truth 문장과 유사한 문장 생성 가능
2) Deep Reinforcement Learning Results
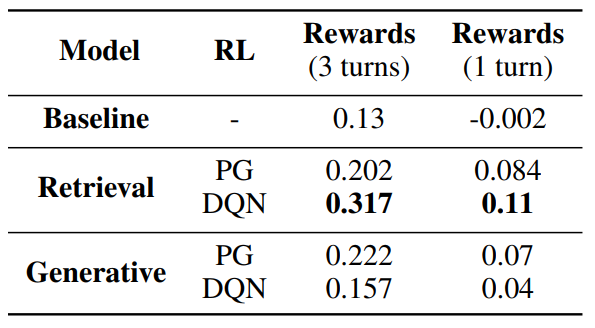
*세 턴의 대화 보상 > 한 턴의 대화 보상: 본 논문에서 제안된 모델이 발화자가 긍정적인 감정 상태로 전환되게 도울 수 있음을 의미(공감할 수 있음을 의미)
*retrieval 모델이 generative 모델보다 평균적으로 좋음
-감정 문장을 생성 시 포함되는 편향이 RL 학습 동안 변동을 일으킴: generator가 옳은 감정으로 문장을 생성하지 못 할 수 있음 => deep RL 학습 시 보상을 증가시키기 위해 옳은 감정을 선택하는 안정적인 정책을 배울 수 없음
3) Human Rating Results
*여러 모델이 반환하는 응답 예제 (각 모델의 설정은 첫번째 테이블과 동일함)

6. 주관적인 한계점 및 의문점
1) Empathatic Dialog Datasets의 구성
*해당 데이터셋은 하나의 상황 당 하나의 감정이 대응됨
=> 한 상황 내에서는 발화자의 문장이나 청취자의 응답이나 모두 같은 감정으로 분류됨
-but 위 논문에서는 하나의 문장(발화)이 들어오면 해당 문장의 감정을 감지하고, "다음 감정"을 예측한다고 함
-현재 감정==다음 감정인데, 다음 감정을 예측한다는 것이 정확히 어떤 과정이지?
2) 모델 및 결과 신뢰성
*모델 제작 구조부터 자세히 설명되어 있지 않아 읽는 입장에서 이해가 되지 않음.
-> 실제 이대로 구현된 모델인지, 해당 모델을 실제로 돌렸는지, 그 결과를 신뢰할 수 있는지 의문
'연구 프로젝트 > 논문 정리' 카테고리의 다른 글
| Deep Reinforcement Learning for Dialogue Generation (0) | 2023.07.17 |
|---|---|
| CHAI: A CHatbot AI for Task-Oriented Dialogue with OfflineReinforcement Learning (0) | 2023.06.12 |
| Open domain dialogue Chatbot(잡담봇 삽질기) 영상 (0) | 2023.05.24 |
| 감정 분석을 위한 BERT 사전학습 모델과 추가 자질 모델의 결합 (0) | 2023.03.12 |