2021. 6. 29. 20:08ㆍ공부한 내용/파이썬 문법
1. Pandas 개요
1) Pandas 개요
-구조화된 데이터를 빠르고 쉬우면서 다양한 형식으로 가공할 수 있는 풍부한 자료 구조와 함수를 제공
-pandas의 기본 구조는 numpy로
2) pandas 특징
-빅데이터 분석에 최적화된 필수 패키지
-데이터는 시계열(series)나 표(table)의 형태
-표 데이터를 다루기 위한 시리즈(series) 클래스 변환
-데이터프레임(dataframe) 클래스 변환
3) pandas 패키지 import
import pandas as pd
import numpy as np
2. 시리즈 클래스(series class)
1) 시리즈 정의
-데이터를 리스트나 1차원 배열 형식으로 series 클래스 생성자에 넣어주면 시리즈 클래스 객체를 만들 수 있다.
-시리즈 클래스는 numpy에서 제공하는 1차원 배열과 비슷하지만, 각 데이터의 의미를 표시하는 인덱스(index)를 붙일 수 있다. 데이터 자체는 값(value)라고 한다.
★시리즈 = 인덱스(index) + 값(value)
#Series 정의하여 생성하기
obj = pd.Series([4, 5, -2, 8])
2) 시리즈 확인
#series의 값만 확인하기
obj.values
#> array([4, 5, -2, 8])
#series의 인덱스 확인하기
obj.index
#> RangeIndex(start=0, stop=4, step=1)
#series의 데이터타입 확인하기
obj.dtypes
#> dtype('int64')
3) 시리즈의 인덱스
-인덱스의 길이는 데이터의 길이와 같아야 하며, 인덱스의 값은 인덱스 라벨(label)
-인덱스 라벨은 문자열 뿐 아니라 날짜, 시간, 정수 등도 가능
#인덱스를 리스트로 별도 지정, 반드시 "" 쌍따옴표 사용
obj1 = pd.Series([4, 5, -2, 8], index=["a", "b", "c", "d"])
4) 시리즈와 딕셔너리 자료형
-Python의 dictionary 자료형을 series data로 만들 수 있다.
-dictionary의 key가 series의 index가 된다.
data = {"Kim": 35000, "Park": 67000, "Joon": 12000, "Choi": 4000}
obj2 = pd.series(data)
-시리즈 이름 지정, index name 지정, index 이름 변경
#시리즈 이름 지정 및 index name 지정
obj.name = "Salary"
obj2.index.name = "Names"
obj2
#> Names
# Kim 35000
# Park 67000
# Joon 12000
# Choi 4000
# Name: Salary, dtype: int64
#index 이름 변경
obj2.index = ["A", "B", "C", "D"]
obj2
#> A 35000
# B 67000
# C 12000
# D 4000
# Name: Salary, dtype: int64
5) 시리즈 연산
-numpy 배열처럼 시리즈도 벡터화 연산 가능
-시리즈의 값에만 적용되며 인덱스 값은 변하지 않는다
obj * 10
#> 0 40
# 1 50
# 2 -20
# 3 80
# dtype: int64
#인덱싱끼리 연산
obj1 * obj1
#> a 16
# b 25
# c 4
# d 64
# dtype: int64
#value 값끼리 연산
obj1.values + obj.values
#> array([8, 10, -4, 16])
6) 시리즈 인덱싱
-시리즈는 numpy 배열의 인덱스 방법처럼 사용 외에 인덱스 라벨을 이용한 인덱싱
-배열 인덱싱은 자료의 순서를 바꾸거나 특정한 자료만 선택 가능
-라벨 값이 영문 문자열인 경우에는 마치 속성인 것처럼 점(.)을 이용하여 접근
a = pd.Series([1024, 2048, 3096, 6192], index=["서울", "부산", "인천", "대구"])
a[1], a["부산"]
#> (2048, 2048)
a[[0, 3, 1]]
#> 서울 1024
# 대구 6192
# 부산 2048
# dtype: int64
a[["서울", "대구", "부산"]]
#> 서울 1024
# 대구 6192
# 부산 2048
# dtype: int64
#라벨 값이 영문 문자열인 경우에는 마치 속성인 것처럼 점(.)을 이용하여 접근
obj2.A
#> 35000
obj2.C
#> 12000
7) 시리즈 슬라이싱(slicing)
-배열 인덱싱이나 인덱스 라벨을 이용한 슬라이싱(slicing)도 가능
-문자열 라벨을 이용한 슬라이싱은 콜론(:) 기호 뒤에 오는 인덱스에 해당하는 값이 결과에 포함
a[1:3]
#> 부산 2048
# 인천 3096
# dtype: int64
#뒤 값까지 결과에 포함
a["부산":"대구"]
#> 부산 2048
# 인천 3096
# 대구 6192
# dtype: int64
8) 시리즈의 데이터 갱신, 추가, 삭제
-인덱싱을 이용하여 딕셔너리처럼 데이터를 갱신(update)하거나 추가(add)
-데이터 삭제 시 딕셔너리처럼 del 명령 사용
#데이터 갱신
a["부산"] = 1234
#del 명령어로 데이터 삭제
del a["서울"]
3. 데이터프레임(DataFrame)
1) 데이터프레임(DataFrame) 개요
-시리즈가 1차원 벡터 데이터에 행 방향 인덱스(row index)라면, 데이터프레임(data-frame) 클래스는 2차원 행렬 데이터에 합친 것으로 행 인덱스(row index)와 열 인덱스(column index)를 가짐
★데이터 프레임 = 시리즈(인덱스(index) + 값(value)) + 시리즈 + 시리즈의 연속체
2) 데이터프레임 특성
-데이터프레임은 공통 인덱스를 가지는 열 시리즈(column series)를 딕셔너리로 묶어놓은 것
-데이터프레임은 numpy의 모든 2차원 배열 속성이나 메서드를 지원
3) 데이터프레임 생성
① 우선 하나의 열이 되는 데이터를 리스트나 일차원 배열로 준비
② 각 열에 대한 이름(label)의 키(key)를 갖는 딕셔너리를 생성
③ pandas의 DataFrame 클래스로 생성
④ 열방향 인덱스는 columns 인수로, 행방향 인덱스는 index 인수로 지정
#DataFrame은 python의 dictionary 또는 numpy의 array로 정의
data = {
'name': ["Choi", "Choi", "Choi", "Kim", "Park"],
'year': [2013, 2014, 2015, 2016, 2017],
'points': [1.5, 1.7, 3.6, 2.4, 2.9]
}
df = pd.DataFrame(data)
#행 방향의 index
df.index
#> RangeIndex(start=0, stop=5, step=1)
#열 방향의 index
df.columns
#> Index(['name', 'year', 'points'], dtype='object')
df.values
#> array([['Choi', 2013, 1.5],
# ['Choi', 2014, 1.7],
# ['Choi', 2015, 3.6],
# ['Kim', 2016, 2.4],
# ['Park', 2017, 2.9]], dtype=object)
4) 데이터프레임 열 갱신 추가
-데이터프레임은 열 시리즈의 딕셔너리로 볼 수 있으므로 열 단위로 데이터를 갱신하거나 추가, 삭제
-data에 포함되어 있지 않은 값은 nan(not a number)으로 나타내는 null과 같은 개념
-딕셔너리, numpy의 배열, 시리즈의 다양한 방법으로 추가 가능
#DataFrame을 만들면서 columns와 index를 설정
df = pd.DataFrame(data, columns=["year", "name", "points", "penalty"], index=(["one", "two", "three", "four", "five"]))
#특정 열만 선택
df[["year","points"]]
#특정 열을 선택하고, 값(0.5)을 대입
df["penalty"] = 0.5
#이렇게 되면 penalty 열의 모든 값이 0.5로 바뀜
#또는 python의 리스트로 대입
df['penalty'] = [0.1, 0.2, 0.3, 0.4, 0.5]
#또는 numpy의 np.arange로 새로운 열을 추가하기
df['zeros'] = np.arange(5)# 또는 index인자로 특정행을 지정하여 시리즈(Series)로 추가
val = pd.Series([-1.2, -1.5, -1.7], index=['two','four','five'])
df['debt'] = val
#연산 후 새로운 열을 추가하기
df["net_points"] = df["points"] - df["penalty"]#조건 연산으로 열 추가
df["high_points"] = df["net_points"] > 2.0
#열 삭제하기
del df["high_points"]
del df["net_points"]
del df["zeros"]#컬럼명 확인하기
df.columns
#> index(['year', 'name', 'points', 'penalty', 'debt'], dtype='object')#index와 columns 이름 지정
df.index.name = "Order"
df.columns.name = "info"
5) 데이터프레임 인덱싱
(1) 열 인덱싱
-데이터프레임을 인덱싱을 할 때도 열 라벨(column label)을 키 값으로 생각하여 인덱싱
-인덱스로 라벨 값을 하나만 넣으면 시리즈 객체가 반환되고 라벨의 배열 또는 리스트를 넣으면 부분적인 데이터프레임이 반환
-하나의 열만 빼내면서 데이터프레임 자료형을 유지하고 싶다면 원소가 하나인 리스트를 써서 인덱싱
df["year"]
#> Order
# one 2013
# two 2014
# three 2015
# four 2016
# five 2017
# Name: year, dtype: int64
#다른 방법의 열 인덱싱
df.year
#> Order
# one 2013
# two 2014
# three 2015
# four 2016
# five 2017
# Name: year, dtype: int64
(2) 행 인덱싱
-행 단위로 인덱싱을 하고자 하면 항상 슬라이싱(slicing)을 해야 한다.
-인덱스의 값이 문자 라벨이면 라벨 슬라이싱
#행 인덱싱은 슬라이싱으로 0번째부터 1번째로 지정하면 1행을 반환
df[0:1]
#0번째부터 2(3-1)번째까지 반환
df[0:3]
★6) loc 인덱싱
-인덱스의 라벨값 기반의 2차원(행, 열) 인덱싱
#.loc 함수를 사용하여 시리즈로 인덱싱
df.loc["two"]
#> Info
# year 2014
# name Choi
# points 1.7
# penalty 0.2
# debt -1.2
# Name: two, dtype: object#.loc 또는 iloc 함수를 사용하여 데이터프레임으로 인덱싱
df.loc["two":"four"]
df.loc["two":"four", "points"]
#> Order
# two 1.7
# three 3.6
# four 2.4
# Name: points, dtype: float64# == df['year']
df.loc[:,'year']
#> Order
# one 2013
# two 2014
# three 2015
# four 2016
# five 2017
# Name: year, dtype: int64#만약 없는 열을 슬라이싱하면?
df.loc[:,['year','names']]
df.loc['three':'five', 'year':'penalty']
#새로운 행 삽입하기
df.loc['six',:] = [2013, 'Jun', 4.0, 0.1, 2.1]
★6) iloc 인덱싱
-인덱스의 숫자 기반의 2차원 (행, 열) 인덱싱
#4번째 행을 가져오기 위해, iloc와 index 번호를 사용
df.iloc[3]
#> Info
# year 2016
# name Kim
# points 2.4
# penalty 0.4
# debt -1.5
# Name: four, dtype: object#슬라이싱으로 지정하여 반환
df.iloc[3:5, 0:2]
#각각의 행과 열을 지정하여 반환하기
df.iloc[[0, 1, 3], [1, 2]]
★7) Boolean 인덱싱
(현재 df)

#year가 2014보다 큰 boolean date
df["year"] > 2014
#> Order
# one False
# two False
# three True
# four True
# five True
# six False
# Name: year, dtype: booldf.loc[df['name'] == "Choi", ['name', 'points']]
#numpy에서와 같이 논리연산 응용할 수 있다.
df.loc[(df["points"] > 2) & (df["points"] < 3), :]
4. 데이터프레임 다루기
1) numpy randn 데이터프레임 생성
#DataFrame을 만들 때 index, column을 설정하기 않으면 기본값으로 0부터 시작하는 정수형 숫자로 입력된다.
df = pd.DataFrame(np.random.randn(6,4))
2) 시계열 날짜 함수 date_range
df.columns = ["A", "B", "C", "D"]
#pandas에서 제공하는 date_range 함수는 datetime 자료형으로 구성된, 날짜/시간 함수
df.index = pd.date_range('20160701', periods=6)
3) numpy로 데이터프레임 결측치 다루기
#np.nan은 NAN값을 의미
df["F"] = [1.0, np.nan, 3.5, 6.1, np.nan, 7.0]
#행의 값중 하나라도 nan인 경우 그 행을 없앤다.
df.dropna(how="any")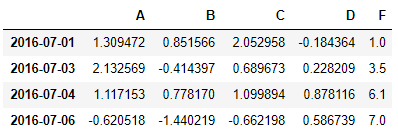
#행의 값의 모든 값이 nan인 경우 그 행을 없앤다.
df.dropna(how='all')
#nan에 특정 value 값 넣기
df.fillna(value=0.5)
4) drop 명령어
#특정 행 drop하기
df.drop(pd.to_datetime('20160701'))
#2개 이상도 가능
df.drop([pd.to_datetime('20160702'), pd.to_datetime('20160704')])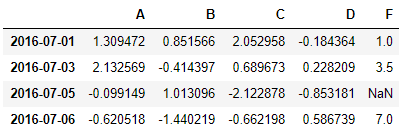
#특정 열 삭제하기
df.drop('F', axis=1)
#2개 이상의 열도 가능
df.drop(['B', 'D'], axis=1)
5. pandas 데이터 입출력
-pandas는 데이터 분석을 위해 여러 포멧의 데이터 파일을 읽고 쓸 수 있다.
-csv, excel, html, json, hdf5, sas, stata, sql
1) pandas 데이터 불러오기 (csv 파일 불러오기)
pd.read_csv('data/sample1.csv')
#c1을 인덱스로 불러오기
pd.read_csv('data/sample1.csv', index_col="c1")
2) pandas 데이터 쓰기 (csv 파일로 저장하기)
df.to_csv("data/sample6.csv")
df.to_csv("data/sample6.csv", index=False, header=False)
3) 인터넷에서 데이터 불러오기
#인터넷 링크의 데이터 불러오기
titanic = pd.read_excel("http://biostat.mc.vanderbilt.edu/wiki/pub/Main/DataSets/titanic3.xls")
titanic.head()
6. 데이터 처리하기
1) 정렬(Sort)
-데이터를 정렬할 때 sort_index는 인덱스 값을 기준으로, sort_values는 데이터 값을 기준으로 정렬
#np.random으로 시리즈 생성
s = pd.Series(np.random.randint(6, size=100))
#value_counts 메서드로 값을 카운트
s.value_counts()
#> 0 22
# 2 19
# 5 17
# 4 15
# 3 15
# 1 12
# dtype: int64
#sort_index 메서드로 정렬하기
s.value_counts().sort_index()
#> 0 22
# 1 12
# 2 19
# 3 15
# 4 15
# 5 17
# dtype: int64
#ascending=False 인자로 내림차순 정리
s.sort_values(ascending=False)
2) apply 함수
-행이나 열 단위로 더 복잡한 처리를 하고 싶을 때는 apply 메서드를 사용
-인수로 행 또는 열을 받는 함수를 apply 메서드의 인수로 넣으면 각 열(또는 행)을 반복하여 수행
*lambda 함수
-파이썬에서 "lambda"는 런타임에 생성해서 사용할 수 있는 익명 함수
-lambda는 쓰고 버리는 일시적인 함수로 생성된 곳에서만 적용
df = pd.DataFrame({
'A': [1, 3, 4, 3, 4],
'B': [2, 3, 1, 2, 3],
'C': [1, 5, 2, 4, 4]
})
#람다 함수 사용
df.apply(lambda x: x.max() - x.min()) #열에 대해 적용
#> A 3
# B 2
# C 4
# dtype: int64
#만약 행에 대해 적용하고 싶으면 axis=1 인수 사용
df.apply(lambda x: x.max() - x.min(), axis=1)
#> 0 1
# 1 2
# 2 3
# 3 2
# 4 1
# dtype: int64#apply로 value_counts로 값의 수를 반환
df.apply(pd.value_counts)
#NaN 결측치에 fillna(0)으로 0을 채우고 순차적으로 정수로 변환
df.apply(pd.value_counts).fillna(0).astype(int)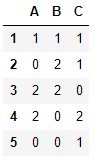
3) describe 메서드
-describe() 함수는 DataFrame의 계산 가능한 값들의 통계값을 보여준다.
df.describe()
7. pandas 시계열 분석
1) pd.to_datetime 함수
-날짜/시간을 나타내는 문자열을 자동으로 datetime 자료형으로 바꾼 후,
-datetimeindex 자료형 인덱스를 생성
date_str = ["2018, 1, 1", "2018, 1, 4", "2018, 1, 5", "2018, 1, 6"]
idx = pd.to_datetime(date_str)
idx
#> DatetimeIndex(['2018-01-01', '2018-01-04', '2018-01-05', '2018-01-06'], dtype='datetime64[ns]', freq=None)
#인덱스를 사용하여 시리즈나 데이터프레임을 생성
s = pd.Series(np.random.randn(4), index=idx)
s
#> 2018-01-01 1.764052
# 2018-01-04 0.400157
# 2018-01-05 0.978738
# 2018-01-06 2.240893
# dtype: float64
2) pd.date_range 함수
-시작일과 종료일 또는 시작일과 기간을 입력하면 범위 내의 인덱스를 생성
pd.date_range("2018-4-1", "2018-4-5")
#> DatetimeIndex(['2018-04-01', '2018-04-02', '2018-04-03', '2018-04-04', '2018-04-05'], dtype='datetime64[ns]', freq='D')
pd.date_range(start="2018-4-1", periods=5)
#> DatetimeIndex(['2018-04-01', '2018-04-02', '2018-04-03', '2018-04-04', '2018-04-05'], dtype='datetime64[ns]', freq='D')'공부한 내용 > 파이썬 문법' 카테고리의 다른 글
| [파이썬] mutable 객체와 immutable 객체의 차이 (0) | 2021.10.28 |
|---|---|
| [파이썬] Pandas 기초 (0) | 2021.07.25 |
| [파이썬] Sympy 기초 (0) | 2021.07.24 |
| [파이썬] Numpy 기초 (0) | 2021.07.24 |
| [파이썬] Numpy - 배열과 벡터 계산 (0) | 2021.06.27 |