[파이썬] T 게임의 <언더월드> 이벤트 여론 분석 - 데이터 시각화 편
[T 게임의 <언더월드> 이벤트 여론 분석 - 데이터 시각화 편]

4. 데이터 시각화
1) 시각화 방향
전처리된 데이터에 머신러닝 알고리즘을 적용하기 전, 데이터 시각화를 통해 데이터가 어떤 형태로 생겼는지 확인해보기로 한다. 특히 텍스트 데이터이기 때문에, 각 SNS 종류마다 단어 빈도수를 확인하고, 이를 워드 클라우드로 그려 시각화하는 것을 목적으로 한다.
2) 시각화 전 준비물
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
from konlpy.tag import Okt
from collections import Counter
import re
from wordcloud import WordCloud
okt = Okt()
runner_data = pd.read_csv("runner_final.csv")
tweet_data = pd.read_csv("tweet_final.csv")
cafe_data = pd.read_csv("cafe_final.csv")시각화 시 다음과 같은 라이브러리와 데이터를 사용했다. 특히 아래의 데이터는 저번 게시글에서 전처리를 완료한 텍스트 데이터이다.
3) 트위터
(코드를 짤 때 트위터 데이터를 먼저 시도했기 때문에 트위터부터...)
전처리 후, 트위터 게시글은 총 22개가 되었다. 위 22개의 게시글로부터 단어 빈도수를 확인하고, 워드 클라우드를 그려보기로 한다. 현재 트위터 게시글 데이터는 다음과 같은 형태로 저장되어 있다.

단어 빈도수를 확인하기 위해서는 위 'tweet'열의 게시글들을 하나의 문자열로 합쳐야 한다. 그러기 위해서 다음의 코드를 사용했다.
tweet_str = ' '.join(tweet_data['tweet']) #한 문자열로 합치기
hangul = re.compile('[^ ㄱ-ㅎ 가-힣]+')
tweet_str = hangul.sub('', str(tweet_str)) #한글과 공백만 남기고 전부 제거이 때, re 라이브러리와 정규표현식을 이용해 단어 중 한글과 공백만 남기고 전부 제거했다.
다음으로는 okt 분석기를 이용해 위 문자열에서 명사를 추출했다.
tweet_noun = okt.nouns(tweet_str) #명사 추출
tweet_count = Counter(tweet_noun) #단어 빈도수 추출
tweet_count_list = tweet_count.most_common(100) #상위 100개의 단어만 저장추출된 명사들의 빈도수를 확인하고, 빈도수가 많은 순서대로 상위 100개의 단어만 추출해 tweet_count_list 변수에 저장했다.

다만 위와 같이 리스트를 확인하면, 단어 빈도수를 확인하는 데 불필요한 단어들이 보인다. 이는 한국어 불용어 사전에 임의의 단어들을 추가하여 제거하기로 한다.
Korean Stopwords
www.ranks.nl
위 사이트에서 한국어 불용어 사전 확인이 가능한데, 이를 직접 리스트로 만들 수도 있고, 혹은 구글링을 조금만 해보면 위 불용어 사전을 텍스트 파일로 공유하는 블로그들이 있다.
다만 위 불용어 외에도 수집하는 데이터에 따라 추가적으로 단어를 제거해줘야 할 필요성이 생긴다. 따라서 위 불용어 사전 텍스트 파일을 리스트로 불러오고, 임의의 단어를 추가해주었다.
#원래의 한국어 불용어 사전
stopwords = []
with open("stopwords_korean.txt", encoding = 'utf-8') as f:
for line in f.readlines():
stopwords.append(line[:-1])
#임의의 단어 추가
stopwords.extend(["언더월드", "테런", "테일즈런너", "이벤트"])위 4개의 단어들은 빈도수로만 따졌을 때 상위를 차지하지만, 여론을 분석할 때는 부적합하기에 불용어 사전에 추가했다.
이제 빈도수 상위 100개의 단어 중 적절한 것만 추출해보기로 한다.
words_list = []
for item in tweet_count_list: #빈도수 상위 100개의 단어들을 for문으로 돌림
if (len(item[0]) > 1) and (item[0] not in stopwords) and (item[1] > 1): #1글자 이상, 불용어 사전에 없는 단어, 빈도수가 2인 단어만 추출
words_list.append(item)수집한 트위터 게시글은 22개밖에 안 되었기 때문에 1번만 등장하는 단어들이 많았다. 따라서 1글자 이상이며, 불용어 사전에 존재하지 않고, 2번 이상 등장한 단어만 추출했다.

이를 그래프로 그리면 다음과 같다. '라라'는 게임 캐릭터의 이름으로서, '언더월드' 이벤트에서 꽤 비중을 차지하는 캐릭터였다. 다음은 언더월드의 OST를 부른 '산들'이 많이 등장했으며, '노잼'이라는 단어가 3번 등장했다.
단어들을 확인하면 '산들', '음악', '노래'와 같이 언더월드의 OST에 관련한 단어들이 많다. 이를 통해 언더월드의 OST가 큰 주목을 받았음을 짐작할 수 있다.
이번에는 이를 워드 클라우드로 그려보기로 한다.
#최종적으로 추출한 단어들을 한 문자열로 합치기
tmp = [i[0] for i in words_list]
cloud_str = " ".join(tmp)
#워드 클라우드 생성
wordcloud = WordCloud(font_path='C://Windows/Fonts/malgun.ttf', background_color='white').generate(cloud_str)
plt.figure(figsize=(20, 20))
plt.imshow(wordcloud)
plt.axis('off')
plt.show()위에서 최종적으로 추출한 단어들을 한 문자열로 합친 후, 이 문자열을 이용해 워드 클라우드를 생성했다. 결과는 다음과 같다.

4) 게임 공식 홈페이지의 자유게시판
이번에는 게임 공식 홈페이지의 자유게시판에서 수집한 게시글을 이용해, 단어 빈도수를 확인하기로 한다. 공식 자유게시판의 게시글은 다음과 같은 형태로 저장되어 있다.

과정은 위 트위터 게시글을 이용해 시각화한 과정과 똑같으므로, 과정 설명은 생략하고 그래프와 워드 클라우드만 설명하기로 한다. 다만 그래프를 그리는 과정에서 필요없는 단어들이 발견되어, 불용어 사전을 다음과 같이 업데이트했다.
stopwords.extend(['진짜', '그냥', '이제', '라가', '생각', '지금', '계속', '때문', '가장', '정말', '처음', '하루', '사실', '느낌', '시작', '초반'])
아래는 게임 공식 자유게시판의 게시글 본문들을 가져와서 단어 빈도수를 확인한 결과다.

'던전', '코인', '리그'와 같이 게임 관련한 단어들이 많으며, 자세히 보면 '문제', '어택', '운영' 등 게임 운영에서의 문제에 관련되어 보이는 단어들도 보인다. 자유게시판에서는 게임 플레이나 아이템 관련한 단어들이 많이 보이나, 이처럼 이벤트의 문제점에 대한 게시글도 종종 올라옴을 확인할 수 있다.
이를 워드 클라우드로 그리면 다음과 같다.

5) 네이버 공식 카페
이번에는 위 게임의 네이버 공식 카페에서 수집한 게시글을 이용해, 단어 빈도수를 확인하기로 한다. 네이버 카페의 게시글은 다음과 같은 형태로 저장되어 있다.

과정은 위와 똑같으므로, 과정 설명은 생략하고 그래프와 워드 클라우드만 설명하기로 한다.
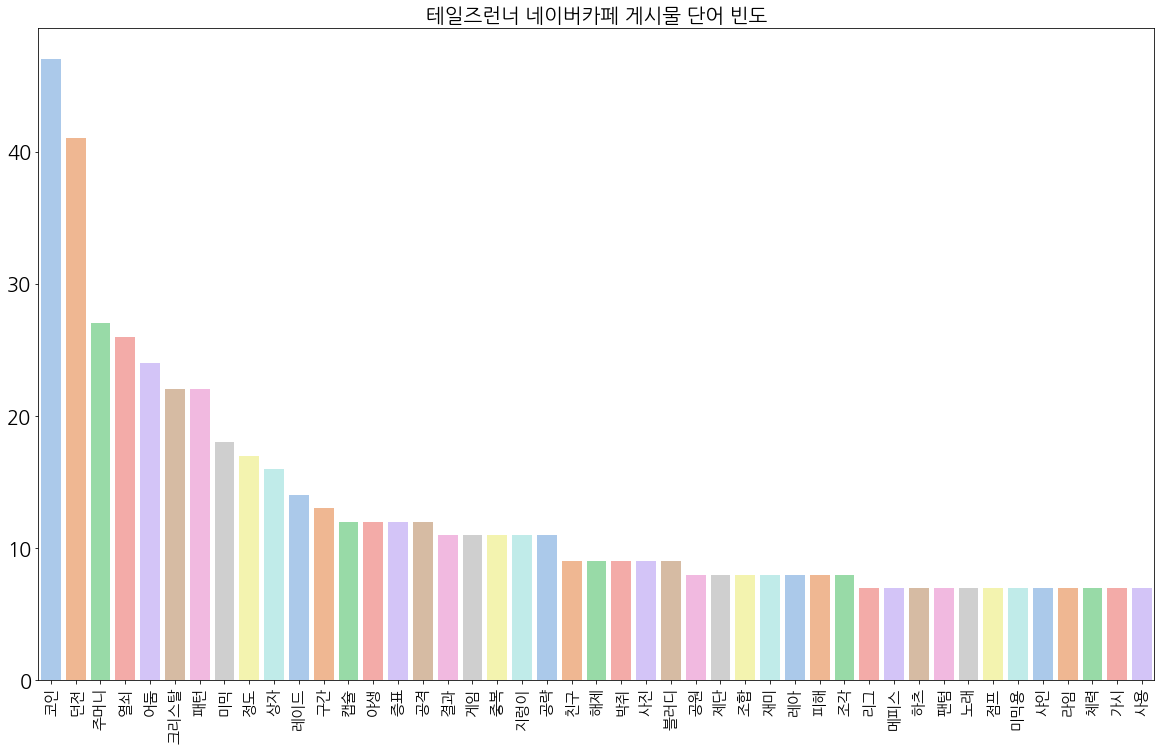
위는 단어 빈도수를 그래프로 그린 결과다. 앞서 공식 자유게시판의 분석 결과와 같이, 게임 플레이 관련한 단어가 상당히 많이 등장했다. 다만 트위터에서는 '노잼'이라는 단어가 상위 100개의 단어 중에 존재했으나, 네이버 카페에는 그와 상반되는 '재미'라는 단어가 상위 100개의 단어에 존재한다.
아래는 이를 워드클라우드로 그린 결과다.

5) 전체 게시글
이번에는 전체 데이터를 모두 합쳐 게시글을 분석하기로 한다. 과정은 위와 똑같기 때문에 과정 설명은 생략한다.
total_str = runner_str + " " + tweet_str + " " + cafe_str전체 게시글에 대한 분석을 위해 다음과 같이 3개의 SNS 게시글(본문)을 문자열로 저장한 변수들을 모두 하나로 합쳤다.
또한 분석하는 과정에서 불필요한 단어들이 추가적으로 보였기에, 다음과 같이 불용어 사전을 업데이트했다.
stopwords.extend(['정도', '나름', '사람'])
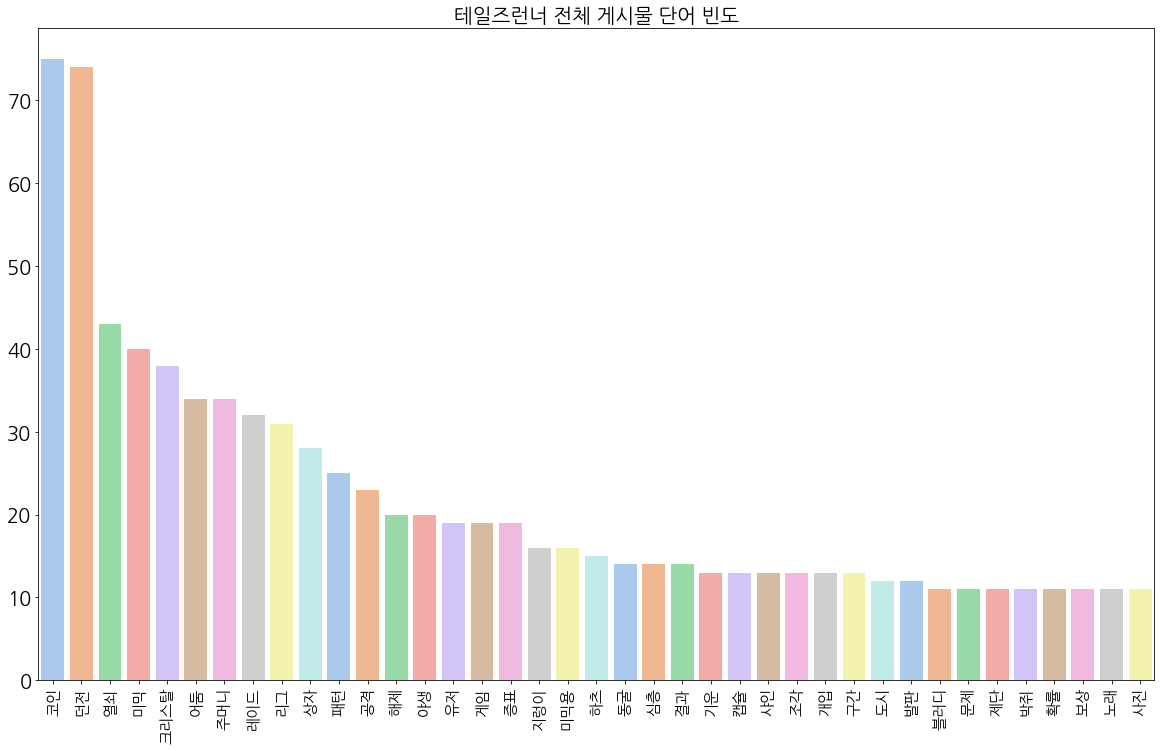
위는 단어 빈도수를 그래프로 그린 결과다. 역시 게임 플레이 관련한 단어들이 많다. 주목할 점은 '중복'이라는 단어로, 그만큼 아이템이 중복으로 나오는 경우가 많음을 가볍게 확인하고 넘어갈 수 있다. 뿐만 아니라 '재미'라는 단어가 상위 100개의 단어들 중에 존재하는 것으로 보아, 이벤트의 재미에 대한 게시글이 많음을 확인할 수 있다. 다만 그것이 긍정적인 반응인지, 부정적인 반응인지는 현재로서는 확신하지 못한다.
아래는 워드 클라우드로 그린 결과다.

6) 시각화 결과
데이터를 정제함으로써 언더월드 이벤트에 관련한 단어들을 많이 추출할 수 있었다. 뿐만 아니라 어느정도 여론을 짐작할 수 있는 단어들도 함께 보면서 간단하게 훑어보는 시간이 되었다.
결론적으로 게임 플레이와 아이템 관련한 단어들이 많았던 만큼, 게임 플레이 혹은 아이템에 관련한 여론을 파악할 수 있을 것이라 예상한다.
-여담-
데이터 정제까지는 상당한 시간을 소요했지만(물론 할 일이 있었던 것도 원인이 됨), 데이터 시각화 과정은 상당히 수월하게 진행되었다. 이제 다음 편에서는 머신러닝을 적용할 예정이다. 아직까지는 감정 분석이나 클러스터링 등 어떤 모델을 적용하는 것이 적합한지 판단하지 못했으나, 아마 클러스터링 위주로 진행될 것 같다.